No products in the cart.
In this text from our Digital Visual Media Anti–Forensics and Counter Anti–Forensics online course by Raahat Devender Singh we discover how deepfakes came to be, and where they're going. Deepfakes, while we're still ahead of the one really huge scandal that will blow everything up, are here to stay. For the time being you mostly hear about them in the context of jokes, experiments, or warnings - and the piece of knowledge below will help you see them exactly for what they are.
Deepfakes: Genesis, by Raahat Devender Singh
You have to know the past to understand the present.
― Carl Sagan
German physicist Georg Christoph Lichtenberg once said, “The most dangerous of all falsehoods is a slightly distorted truth.” In our multimedia–driven society, where photographic and video evidence enjoys an epistemologically unique status, this observation is exceedingly ominous.
Videos carry within themselves enough information to help us form an opinion of the reality of the event being depicted in the scene, and it is this information carrying capacity of theirs that leads us to recognize them as not only self–sufficient but also self–evident. But this tendency to believe what we see in a video renders us susceptible to deception, and given the sheer rate of extant technological progress and mankind’s never–ending desire for mischief, deception comes very easily.
When BuzzFeed CEO Jonah Peretti and actor and filmmaker Jordan Peele created the fake Obama PSA in April, it engendered a wave of wonder and amazement, which was replaced by a wave of trepidation and creeping vexation when the reality of the situation began to sink in. This video quickly became one of the most recognizable examples of deepfakes, aside from, of course, all the videos people created by replacing various actors’ faces in movie clips with those of Nicholas Cage for some reason (example can be found here and here).
Deepfake, which is a portmanteau of ‘deep learning’ and ‘fake’, refers to the artificial intelligence–based human image synthesis technique that is used to combine and superimpose existing images and videos onto source images or videos. But the origin of such fake videos far predates the concept of deep learning. This chapter will take us on a journey to learn more about the origin and history of deepfakes. But first, let’s take a look at a few snapshots from some famous deepfakes.

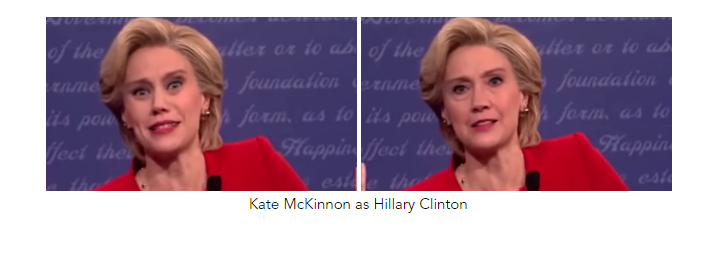

An Introduction to Deepfakes and Fake Videos
Before delving any further into the realm of fake videos, let’s take a quick look at the various operations that are involved in the generation of fake videos.
- Face replacement, aka face swapping, refers to the process of replacing a person’s face (or parts of a face) in a target video with that (or those) of another from a source video or several source images. This concept is analogous to the image–based face–swap operation, whereby faces of people in digital images are replaced by faces of other people.
- Depending on whether or not the target person in the fake video engages in a monologue or a dialogue, the mouth of the person may need to be manipulated accordingly. This is done with the help of an operation known as facial animation. In order to create a more realistic fake video, facial animation is sometimes performed in conjunction with expression animation, whereby the facial expressions of the target person are also manipulated along with their mouth. Facial animation can also be used to synthesize an entire face, which can then be superimposed onto the face of a target person (who can either be the same as the source person or someone entirely different).
- Facial re–enactment, which refers to the process of replacing the facial expressions of a target person in the given video with those of a source person, also falls under the category of facial animation.
- Facial (and expression) animation can also be performed in combination with another operation known as speech animation, aka lip–sync synthesis, which involves one of two things. Either the audio in the target video is replaced with another audio clip (of the target person speaking at some other moment in time or in another video), or the audio in the target video is replaced by an entirely falsified audio. Please note that the latter is subject to availability of a good impressionist (like in the case of the Fake Obama PSA), or access to Adobe VoCo or WaveNet.
Various combinations of the aforementioned operations can be used to create fake videos, in which either the face and/or expressions of a target person are manipulated, or the involvement of a person in a particular activity is falsified. The timings or context of the words spoken by the target person in the video can also be altered and/or falsified. It is also possible to create a video with an entirely bogus speech.
History of Deepfakes
From a technical standpoint, the notion of fake videos is rooted in the earliest innovations in the domain of CG–assisted creation of photorealistic digital actors, a task that was spearheaded by Parke in 1972. In 1990, Williams introduced the term ‘facial animation’ to the computer graphics community. His paper described a way to replace faces in videos by first acquiring a 3D face model of an actor, animating the face, and then relighting, rendering, and compositing the animated model into the source video. The 3D face model was captured using markers, which is why this scheme is referred to as ‘performance driven facial animation’. The same underlying principles were later used in Guenter et al. 1998 and Bickel et al. 2007.
Aside from markers, other ways to create 3D face models include use of structured light, as demonstrated in Zhang et al. 2004, Ma et al. 2008, Li et al. 2009, and Weise et al. 2009, and passive multi–view stereo approaches, like those developed in Jones et al. 2006, Bradley et al. 2010, and Beeler et al. 2011. Such model–based face replacement strategies are known to achieve remarkable realism; some notable examples include ‘Virtual History: The Secret Plot to Kill Hitler’, ‘The Digital Emily Project’, and for recreation of actors and stunt–doubles in movies. Let’s discuss some of these examples in more detail.
Virtual History: The Secret Plot to Kill Hitler, a TV special created by The Moving Picture Company, which aired in October 2004 on Discovery, was groundbreaking in many ways. It was the first TV program to use Computer Generated Imagery (CGI) and Facial Motion Capture (FMC) to create realistic historical figures (Hitler, Roosevelt, and Churchill), and the first to create imagery indistinguishable from 1940’s color archive footage. The process began with the selection of suitable actors (with compatible head dimensions) to portray the chosen historical figures. Plaster casts of actors’ heads were then created and the historical figures’ faces were sculpted directly on the cast. The resulting maquettes were laser–scanned to obtain CG models. The face area was then extracted and refined to create a workable mesh.

The static CG face models were then textured and shaded. For reference, archival material of the three figures was used. Details like color of the skin, reaction to light (diffuse, specular, translucence), wrinkles, pores, other distinguishing marks, facial hair (eyebrows, moustache), and glasses were also modeled.

The next step was tracking. During the live action shoot, the actors wore custom–made facial rigs with attached markers, which facilitated the subsequent tracking of their head within the shot.

Facial motion capture was the next step. First, dots were placed on the actors’ faces to trace specific movements. As each actor spoke, a grid was projected onto his face as a reference guide to correlate movement from frame to frame. For each frame, about 30,000 points were captured – 100 times more than with traditional motion capture techniques of that time.
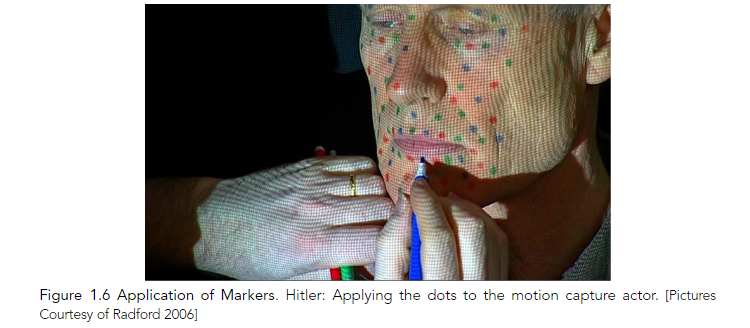


The static textured face meshes were tracked onto the live action actors in their respective shots, and then lighting began. The motion–capture data (which provided animated facial meshes) and the corresponding driven CG meshes were then composited into the live action footage.

The final step of the process was grading; the footage was manipulated to resemble authentic 1940’s color archive material.


In The Digital Emily Project, Image Metrics and the University of Southern California’s Institute for Creative Technologies (USC ICT) animated a digital face using 3D facial capture, character modeling, animation, and rendering. The project aimed to cross the “uncanny valley”, which is a hypothesized relationship between the degree of an object's resemblance to a human being and the emotional response to such an object. The concept of the uncanny valley suggests that computer generated images or humanoid objects that appear almost, but not exactly, like real human beings, elicit uncanny or strangely familiar feelings of eeriness and revulsion in observers. The valley denotes a dip in the human observer's affinity for the replica, a relation that otherwise increases with the replica's human likeness.
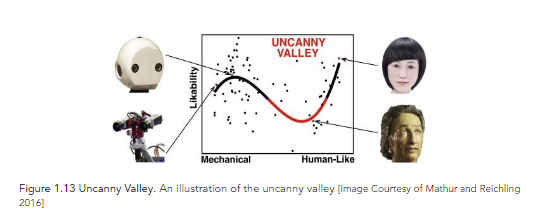
Here are some examples of the uncanny valley in action, mostly from video games.

The Digital Emily Project, which is what we were talking about before we got distracted by horrifying video game characters and murderous clowns, generated one of the first photorealistic digital faces to speak and emote convincingly in a medium close–up setting. The process began with the acquisition of 15 high–resolution scans of actress Emily O’Brien’s face under different lighting conditions to capture the face’s geometry and reflectance.


Using the images obtained during the scanning process, specular maps and high–resolution 3D geometry of the face were obtained.

Emily’s was scanned in 33 different facial expressions, after which the facial animation process began, the main steps of which were: preprocessing the facial scans, building the blendshapes (blendshape interpolation can be traced back to Parke’s pioneering work in facial animation [Parke 1972, Parke 1974]), adding facial details with displacement maps, and adding eyes and teeth.


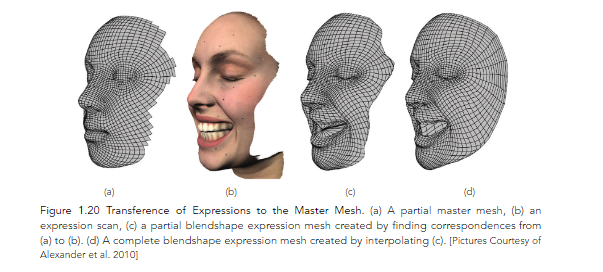

Although the Digital Emily animation did not perfectly reproduce every subtlety of the real Emily’s performance, it was pretty close.
Aside from the model–based strategies described above, another method of face replacement is the image–based approach, which does not involve creation of a 3D face model of the target person. In Bregler et al. 1997 and Ezzat et al. 2002, the authors replaced the mouth region of the target person in the video to match phonemes of novel audio input with the help of a database containing training images of the same person. Flagg et al. 2009 used video textures to generate plausibly articulated body movements.
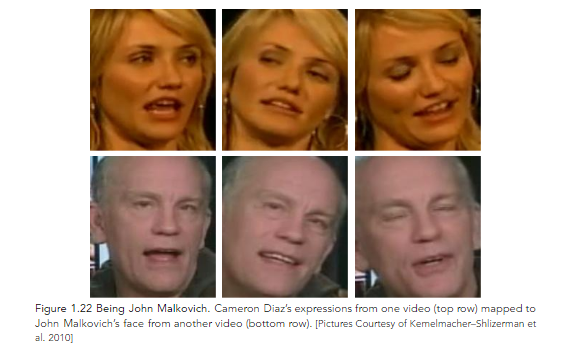
Kemelmacher–Shlizerman et al. 2010 made use of large collections of images and videos of celebrities and replaced their photos in real time based on similarities in expressions and pose. Figure 1.22 illustrates some results of this method.
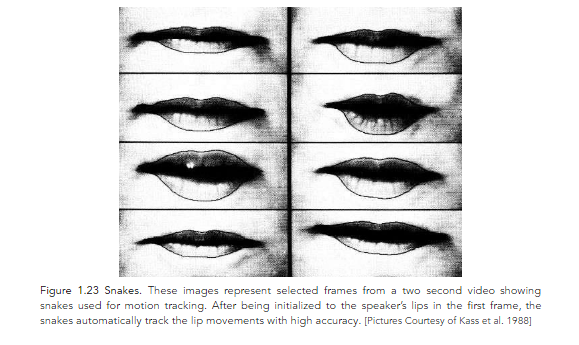
Another way to replace faces of people in videos is to use image–based face capture approaches that build morphable 3D face models of the target person using source images of the same person without the help of any kind of marker or specialized face scanning equipment. The foundational concept upon which marker–less face capture schemes were built, was first introduced by Kass, Witkin, and Terzopoulos in 1988. The authors thereof developed active contour models, which they called ‘snakes’. Snakes were energy–minimizing splines guided by external constraint forces and were influenced by forces that pulled them toward features such as lines and edges. These snakes were shown to have several applications including, but not limited to, detection of edges, lines and subjective contours, motion tracking, and stereo matching.
Further advances in the human face modeling domain were made in Essa et al. 1996, DeCarlo and Metaxas 1996, Pighin et al. 1998, and application of these advances for face replacement, facial animation, and facial re–enactment were demonstrated in Pighin et al. 1999, Blanz et al. 2003, Joshi et al. 2003, Vlasic et al. 2005, Dale et al. 2011, Garrido et al. 2014, Thies et al. 2015, Averbuch–Elor et al. 2017, Suwajanakorn et al. 2017, Thies et al. 2018, and Rössler et al. 2018. Some illustrative examples of the processes described in these papers are presented next.
In Blanz et al. 2003, the authors proposed a system for photorealistic animation that could be applied to any face shown in a picture or a video. In order to animate novel faces, their system transferred mouth movements and expressions across individuals, based on a common representation of different faces and facial expressions in a vector space of 3D shapes and textures. This space was computed from 3D scans of neutral faces and facial expressions (Figures 1.24 and 1.25).

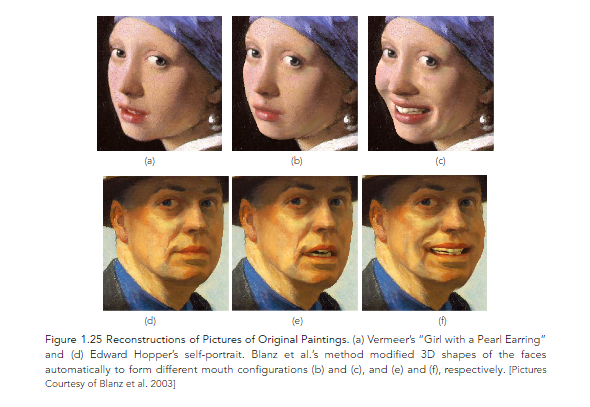
And as long as we’re on the subject of animating famous paintings, let’s check out the following examples, where powers of manipulation have been put to great use.


And why limit yourselves to just famous paintings when you can also do this:


Now returning to our original discussion. The authors in Vlasic et al. 2005 developed a face transfer method, whereby a video–recorded performances of one individual could be mapped to the facial animations of another. The method was designed to first extract visemes (i.e., speech–related mouth articulations), expressions, and 3D pose from monocular video or film footage, which were then used to generate and drive a detailed 3D textured face mesh for a target person. The 3D textured face mesh was then seamlessly rendered back into the given video. The underlying face model of this method automatically adjusted for the target person’s facial expressions and visemes. The performance data could also be edited to change the visemes, expressions, pose, or even the identity of the target person (Figure 1.28).

Figure 1.28 Face Transfer. In this example, the pose and identity of the ‘Target Person’ from one video is combined with expressions from the video of ‘Source Person 1’ and visemes from the video of ‘Source Person 2’ to get a composite result, which is blended back into the original video. [Pictures Courtesy of Vlasic et al. 2005]
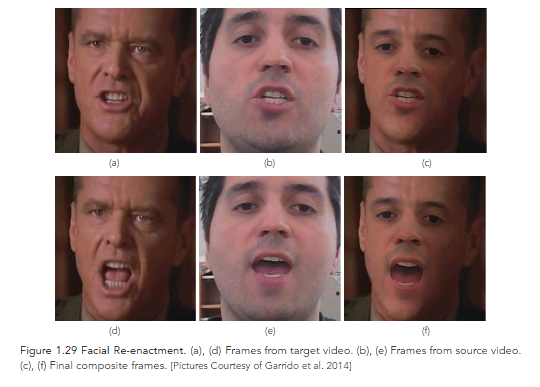
The image–based automatic face re–enactment scheme presented in Garrido et al. 2014 was designed to replace the face of an person in a given target video with that of a source actor/user from a source video, while preserving the original performance of the target person (Figure 1.29).
The technique proposed in Thies et al. 2015 was designed to transfer facial expressions from a person in a source video to a person in a target video in real–time, thereby enabling ad–hoc control of the facial expressions of the target person in a photorealistic manner. To achieve this, the authors captured the facial performances of the source and target subjects in real–time with the help of a commodity RGB–D sensor. Then for each frame, they jointly fit a parametric model for identity, expression, and skin reflectance to the input color and depth data, and also reconstructed the scene lighting. For expression transfer, they computed the difference between the source and target expressions in parameter space, and modified the target parameters to match the source expressions (Figure 1.30).

Like all great things that are fun to play with but will eventually destroy us all, the idea for this type of real–time face swap came from TV. This kind of technology was first alluded to in Episode 1 of Series 1 of the show ‘Black Mirror’, wherein a visual effects expert was asked to superimpose the head of a subject onto the body of a live performer in real–time.

As life imitates art, so does science science–fiction. (Trust me. That sentence makes sense.)
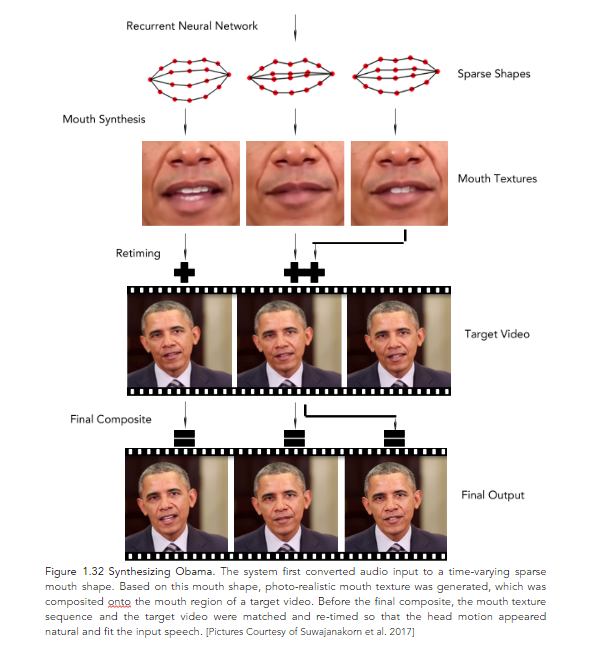
Moving on. In Suwajanakorn et al. 2017, the authors, using several hours of his weekly address footage, synthesized a high quality video of Barack Obama speaking with accurate lip–sync. The process is illustrated in Figure 1.32 below.
The authors in Averbuch–Elor et al. 2017 presented a technique to automatically animate still portraits, making it possible for the subject in the picture to come to life and express various emotions. They used a driving video of a person other than the one in the portrait and transferred their expressiveness to the target portrait. In contrast to previous works that required an input video of the target face to re–enact a facial performance, this technique used only a single picture of the target person. Figure 1.33 illustrates the process.

Figure 1.34 presents some sample results obtained by the aforementioned facial animation process.

Facebook developed a technology similar to the one presented in Averbuch–Elor et al. 2017. It was an inpainting technique that was designed to replace closed eyes in pictures with open ones (because that’s a really important thing for mankind to be doing). They taught a Generative Adversarial Network (GAN) to fill in missing regions of an image (eyes in this case) using exemplars (sample images). Some results have been presented in Figure 1.35.

Now if only Facebook could do something about people’s constant refusal to open their eyes for the camera, so that moments like Wesley Snipe’s CGI eye–opening in ‘Blade: Trinity’ never have to be repeated again (even by 2004 standards, that CGI was horrific). This task should be next on their to–do list, right after they wind up some of their other projects like harvesting user data, manipulating voters, empowering authoritarians, inflaming racial tensions, and provoking ethnic violence.
Finally, we arrive at deep learning–based fake video creation. Deep learning has been finding increased utility in digital visual content manipulation these days, but so far it has mostly been used for image manipulation (Antipov et al. 2017, Hunan et al. 2017, Lu et al. 2017, Upchurch et al. 2017, Lample et al. 2017, and Karras et al. 2017). As of yet, deepfake videos, such as the fake Obama PSA created by Peele and Peretti, the fake Trump video created by Russian–linked trolls, the fake Trump video created by the Belgian political party Socialistische Partij Anders, aka sp.a, all the crimes against humanity people insist on calling “DeepCages”, and the fake celebrity pornographic videos created using FakeApp, are the only available exemplifications of deep learning–assisted fake videos; no technical papers documenting the creation of these videos have been made available.
Recently, an unsupervised video retargeting method was proposed in Bansal et al. 2018, where the authors used cycle–GAN and Pix2Pix to translate content from one video to another while preserving the style native to the target video. The authors demonstrated the applicability of this method to perform operations like transferring contents of John Oliver’s speech to Stephen Colbert in a way that the generated content appears to be in Colbert’s speech style, or generating synthetic sunrises and sunsets, and although the results of this method are far from perfect, it’s safe to say that it’s only a matter of time before that changes.
Summary
In this chapter, we explored the origin and history of deepfakes and familiarized ourselves with various technologies that are used to create fake videos. We also examined how each process involved in the creation of a typical fake video is performed and how these processes continue to evolve with time. In the next chapter, we will learn some tactics that can be used to expose fake videos. As examples, we will consider some viral YouTube videos.
[custom-related-posts title="Related Posts" none_text="None found" order_by="title" order="ASC"]
Author
Latest Articles
 BlogApril 7, 2022Detecting Fake Images via Noise Analysis | Forensics Tutorial [FREE COURSE CONTENT]
BlogApril 7, 2022Detecting Fake Images via Noise Analysis | Forensics Tutorial [FREE COURSE CONTENT] BlogMarch 2, 2022Windows File System | Windows Forensics Tutorial [FREE COURSE CONTENT]
BlogMarch 2, 2022Windows File System | Windows Forensics Tutorial [FREE COURSE CONTENT] BlogAugust 17, 2021PowerShell in forensics - suitable cases [FREE COURSE CONTENT]
BlogAugust 17, 2021PowerShell in forensics - suitable cases [FREE COURSE CONTENT] OpenMay 20, 2021Photographic Evidence and Photographic Evidence Tampering
OpenMay 20, 2021Photographic Evidence and Photographic Evidence Tampering
Subscribe
Login
0 Comments